The Magic of Consistent Hashing: A Secret Weapon for Efficient Load Balancing


Consistent Hashing is one of the famous terms used in system design.
Is it used in many other important concepts like load balancing, sharding or any other uniform segregation distribution.
Let's explore why it is so important and why it is used again and again but before moving on to consistent hashing, first, let us revise or get ideas about some topics.
Hashing
Hashing is a process of converting an input (or 'message') into a fixed-size string of text, also known as a 'hash value', 'digest' or 'checksum'. The main idea behind hashing is to create a unique representation of the input data in a way that can be used for various purposes, such as data integrity validation, searching, indexing, and more

.
There are several types of hashing algorithms, each with its strengths and weaknesses. Some common types of hashing algorithms include:
MD5 (Message-Digest Algorithm 5): This is a widely used hashing algorithm that generates a 128-bit hash value. It is fast and relatively secure but is vulnerable to collision attacks, where two different inputs can produce the same hash value.
SHA-1 (Secure Hash Algorithm 1): This is another widely used hashing algorithm that generates a 160-bit hash value. It is considered to be more secure than MD5 but is also slower.
SHA-2 (Secure Hash Algorithm 2): This is a family of hash functions that includes SHA-224, SHA-256, SHA-384, and SHA-512. These algorithms generate hash values of different sizes, ranging from 224 to 512 bits, and are considered to be more secure than SHA-1.
SHA-3 (Secure Hash Algorithm 3): This is a family of hash functions that were selected through a competition organized by the National Institute of Standards and Technology (NIST). SHA-3 functions are designed to be more secure and more efficient than their SHA-2 counterparts.
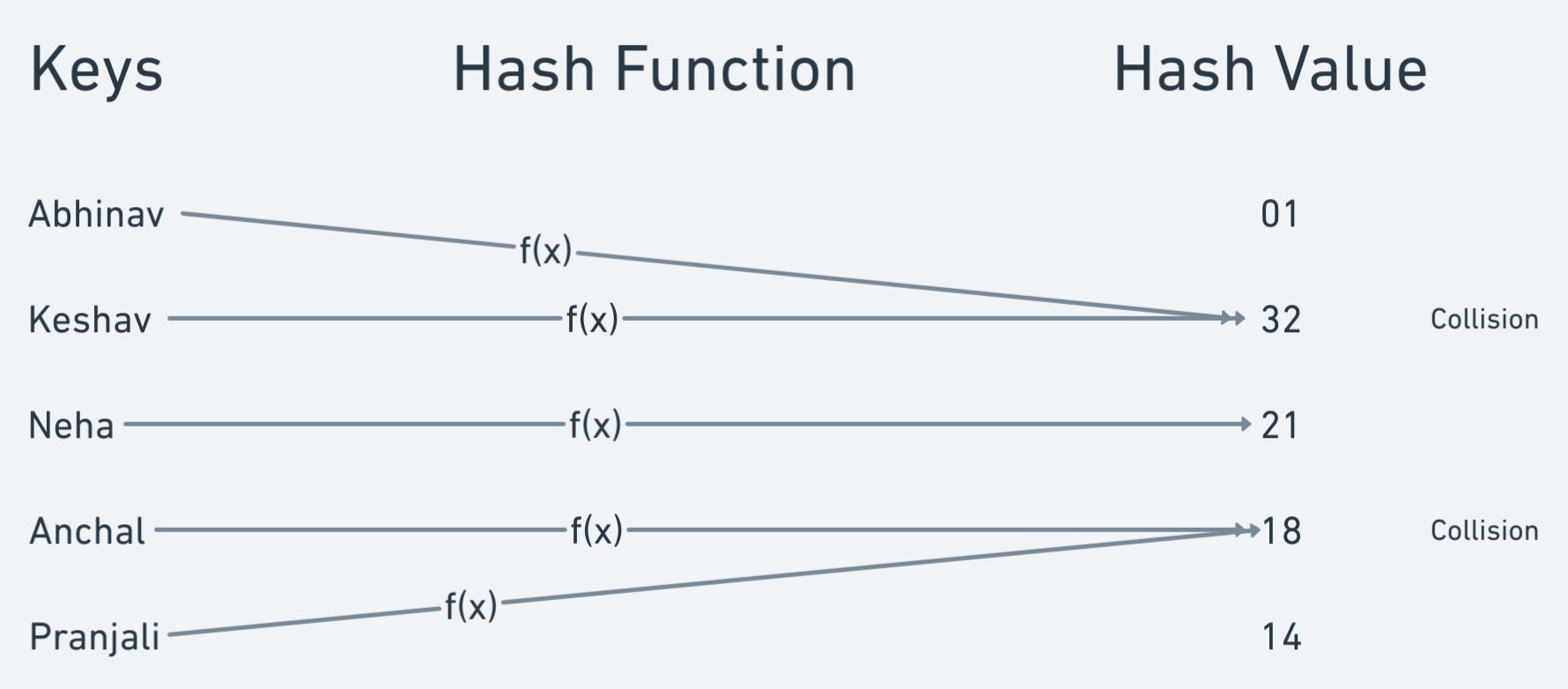
Collisions in Hashing
A collision in hashing occurs when two different input values produce the same hash output. Hashing algorithms are designed to produce a unique output for every unique input, but because the number of possible input values is typically much larger than the number of possible hash outputs, collisions are bound to occur. This can be problematic in some applications, such as digital signatures, where different inputs must result in different outputs.
There are several ways to deal with collisions in hashing, including using a larger hash output size, using a more secure hashing algorithm, or employing a technique called "salting" to ensure that even if two inputs produce the same hash, they will still have different outputs. Despite these measures, it is generally recommended to assume that collisions are possible in any hashing system and to design systems with this in mind.
Distributed Hashing
Distributed Hashing is a technique used to distribute data across a network of nodes in a way that allows for efficient and scalable access to the data. It is commonly used in distributed systems such as NoSQL databases, peer-to-peer networks, and cloud computing environments.
The basic idea behind distributed hashing is to map data items to nodes in the network using a hash function. The hash function takes the data item as input and outputs a value that is used to determine which node in the network should store the data. This mapping is known as a hash table, and it provides a way to distribute the data evenly across the nodes in the network.
Advantages of using distributed hashing include improved performance and scalability, as well as increased reliability and fault tolerance. By distributing the data across multiple nodes, the system can handle larger amounts of data and higher levels of traffic without becoming overwhelmed. Additionally, if one node fails, the data can still be accessed from other nodes in the network, ensuring that the system remains available even in the event of failures.
Now let's take an example.
Suppose we have N Servers from S1 to Sn and we need to distribute incoming user requests on those servers evenly based on the user email address.
We have a hashing function H(x) which hashes the key and returns a unique number considering that collision does not occur.
To distribute evenly we take modulo from N.

index = hash(key) modulo N
The above example shows a uniform distribution of the keys over the N\=5 servers.
The distribution is uniform because of two factors, the first is a uniform hash function and the second is the modulus factor which is the number of servers itself.
Rehashing
Rehashing in a distributed system refers to the process of redistributing key-value pairs in a hash table across multiple nodes in a network. It is often used in distributed hash tables (DHTs) and other distributed data structures to ensure efficient distribution and utilization of resources, improve scalability, and maintain consistency.
The goal of rehashing is to evenly distribute the data across the nodes in the system while minimizing the need to move large amounts of data. This is typically achieved by periodically reassigning keys to different nodes based on a consistent hash function. The hash function maps the keys to nodes in such a way that keys that are close to each other in the hash space are assigned to the same node, which helps to reduce the amount of data that needs to be moved during a rehash.
Rehashing can be triggered by various events such as the addition or removal of nodes from the system, changes in the network topology, or updates to the hash function. It can be a complex process, especially in large-scale systems, as it may require coordination and communication between nodes, as well as consistency checks to ensure that all nodes have the same view of the data.
Now the problem is rehashing is that if any server is added or removed then N changes and to maintain uniformity server have to redistribute every key according to the new N. This is overhead on the server and can act as a bottleneck while scaling distributed systems . To solve this problem a well know architecture is used called consistent hashing
Here comes the Consistent Hashing
This problem is solved by consistent hashing by providing a distributed scheme in which hashing does not directly depends on the number of servers N.
Consistent Hashing is a distributed hashing scheme that operates independently of the number of servers or objects in a distributed hash table by assigning them a position on an abstract circle, or hash ring. This allows servers and objects to scale without affecting the overall system.
In general, only the K/N number of keys are needed to be remapped when a server is added or removed. K is the number of keys and N is the number of servers ( to be specific, the maximum of the initial and final number of servers)

In the above diagram, we can see that Key 1 is allocated with Server 1, Key 2 to S2 and all others.
In this, the keys which are placed on the abstract ring are assigned to the next immediate right server in the clockwise direction.
If in case S1 is removed then K1 will be redirected to the next left server which is S2 and no other keys are affected.
Similarly, if a new Server is added then the keys left to it will now be assigned to the new server.
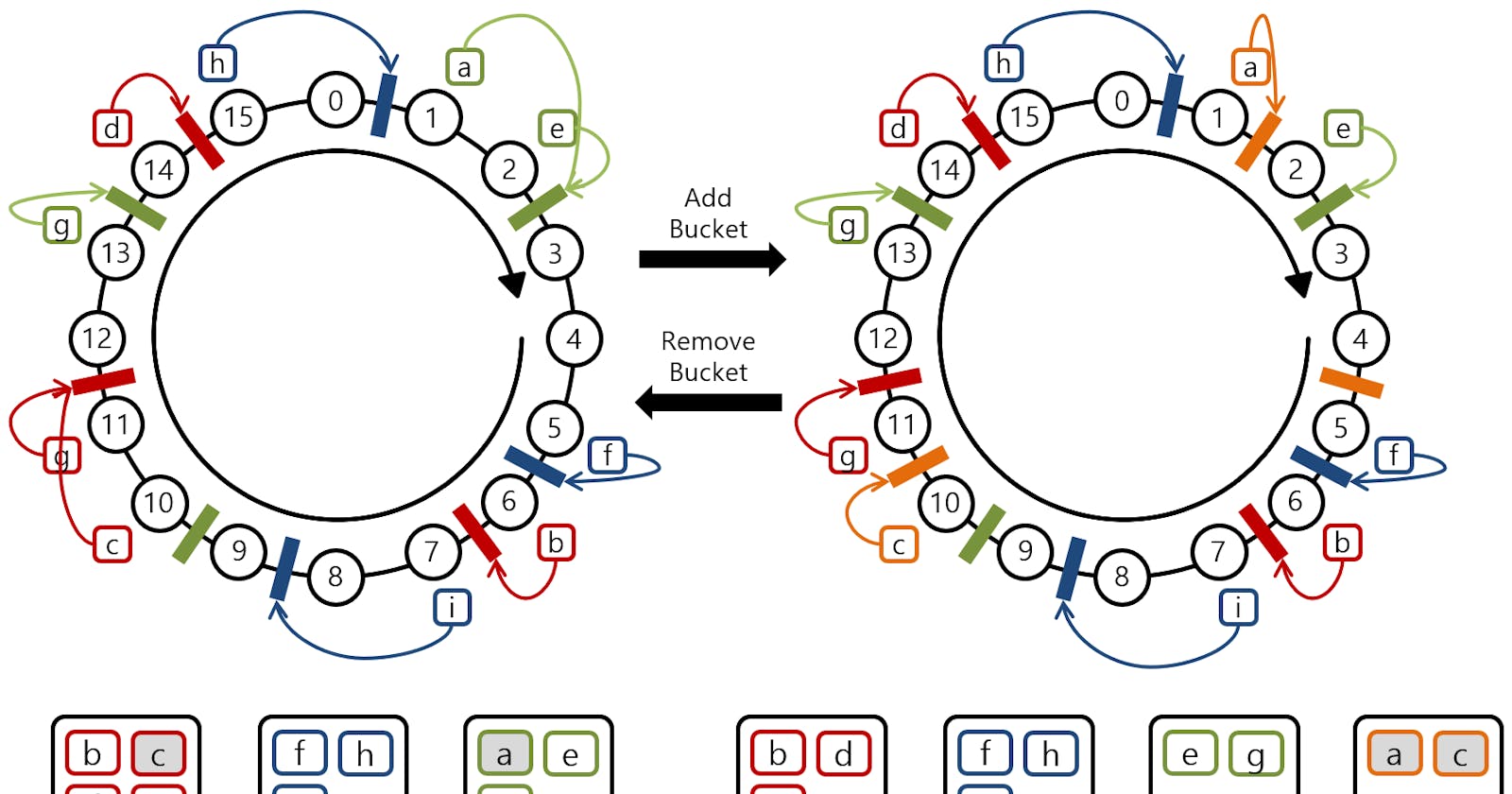
To maintain more and more uniformity replicas of each server are added to the ring. These replicas are called virtual nodes.
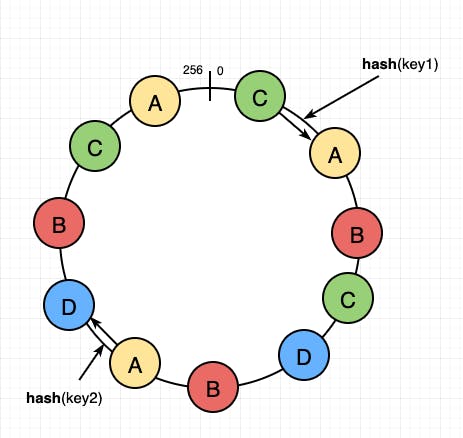
In the above diagram, the yellow colour represents the main Server A and replicas of the same server and the same for the other servers B, C, and D.